■ 상관 분석
: 두 변수 간에 어떤 선형적 또는 비선형적 관계를 갖고 있는지를 분석하는 방법
선형적 : 직선모양
비선형적 : 직선모양 X
※ 상관 관계
: 한쪽이 증가하면 다른 쪽도 증가하거나 반대로 감소되는 경향을 인정하는 두 양 사이의 통계적 관계
→ 두 변수가 선형 관계 or 비선형 관계에 있는지 파악
※ 상관 계수
: 두 변수 사이의 상관성을 나타내며 일반적으로 피어슨 상관계수를 사용
: 즉, 두 변량 X, Y 사이의 상관관계의 정도를 나타내는 수치(계수)

→ 일반적으로 상관계수가 0.7 이상이면 강한 양의 상관관계
→ 상관계수가 -0.7 이하면 강함 음의 상관관계를 갖는다.
→ 상관계수 = 0 이라면 무상관

→ 상관계수가 -1 or +1에 가까울 수록 두 변수 간의 관계가 강하다는 뜻이지만, 두 변수 간의 인과관계(어느 변수가 원인이고 결과인지)는 알 수 없다.
→ 즉, 상관관계가 높다고해서 서로간의 인과관계를 뜻하는 것은 아니다.
① 상관계수 표를 만들어서 분석하기
파일 탭 → 옵션 → 추가기능 → 분석도구 → 이동 → 분석도구 체크
데이터 탭에 데이터 분석 옵션이 생긴다. 이를 이용하여 상관분석이 가능하다.
② CORREL(범위1, 범위2) 함수 사용하여 상관계수를 구할 수 있다

→ 상관계수 표에 조건부서식을 적용하여 -1 ~ +1 사이의 값에 바탕색으로 강조하는 것도 좋은 방법이다.
■ 분산 분석
: 두 개 이상 다수의 집단을 비교하여 평균의 차이가 있는지를 검정한다.
ex)
A 환자군 → 약 처방 O → 간 수치 평균 (C1)
B 환자군 → 약 처방 X → 간 수치 평균 (C2)
C1과 C2는 차이가 있는가?
cf) 귀무 가설 : 일반적으로 인정되는 사실
cf) 대립 가설 : 우리가 주장하는 가설 (귀무 가설에 대립하는 명제)
※ 분산 분석의 방법
: 집단의 개수에 따라 분산 분석의 방법이 다르다
① 집단이 2개일 때 → T-test
② 집단이 3개 이상일 때 → ANOVA (ANalysis Of VAriance)
● F-검정
: 두 집단의 분산이 같은지 여부를 검정 (데이터 분석 옵션을 사용)
등분산성 : 분산이 같음
이분산성 : 분산이 다름
→ P-value가 0.05보다 크면 두 집단의 분산은 같다. → t-검정 (등분산 가정 두 집단)
→ P-value가 0.05보다 작으면 두 집단의 분산은 다르다. → t-검정 (이분산 가정 두 집단)

★ F-검정을 통해 P-value의 수치를 보고 어떠한 t-검정을 할 것인지 판단한다.
● T-test
: 두 집단의 평균이 유의미한 차이가 있는지 검정
→ P-value가 0.05보다 크면 두 집단의 평균은 같다.
→ P-value가 0.05보다 작으면 두 집단의 평균은 다르다.
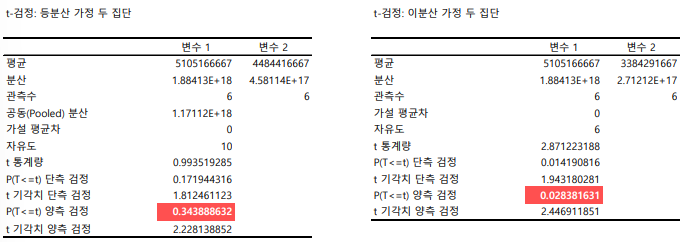
→ 집단1은 그대로 두고 집단2에 어떤 처리를 하거나 영향을 주는 사건이 발생했을 때, T-test의 P값이 0.05보다 작으면, 집단2에 시행한 처리나 발생한 사건이 두 집단의 평균 차이에 유의미한 영향을 미쳤다고 해석한다.
■ 회귀 분석
: 두 개 이상의 연속형 변수(수치)인 종속 변수와 독립 변수 간의 관계를 파악하는 분석
: 둘 또는 그 이상의 변수 사이의 관계, 특히 변수 사이의 인과관계를분석하는 추측 통계의 한 분야
Y = aX + b
Y : 종속 변수 (알고 싶은 값)
X : 독립 변수 (알고 있는 값)
※ 회귀 분석의 목적
① 두 변수 간의 관계 파악
② 미래 값 예측

※ 회귀 분석의 종류
독립 변수(X)의 개수에 따라 단순/다중 회귀 분석으로 구분
① 단순 회귀 분석
→ 독립 변수(X)가 한 개일 때 사용
→ 독립 변수(X)가 변할 때, 종속 변수(Y)값이 어떻게 변하는지를 가장 잘 설명해주는 직선을 찾아 분석하는 방법
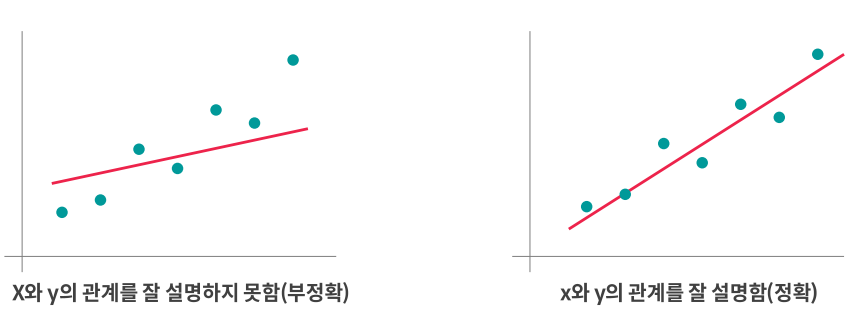
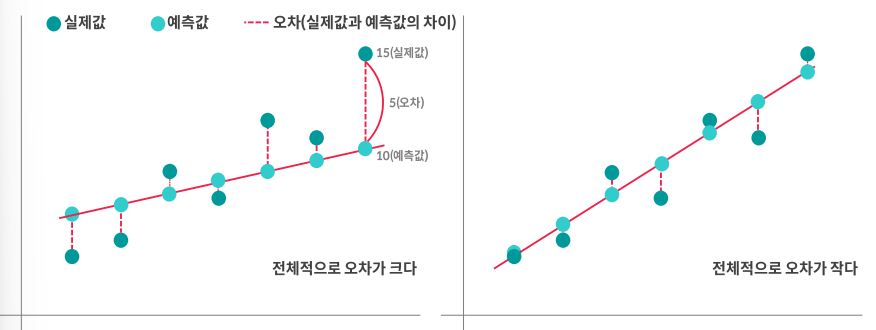
*최소 제곱법(LSE, Least Square Estimation)
→ 전체적으로 오차가 작은 직선을 찾는다
= 빨간 점선의 길이의 합이 가장 작은 직선
= 단, 오차는 +,-가 있으므로 오차를 제곱한 합이 가장 작은 직선을 선택
※ 데이터 분석 옵션을 사용한 이미지
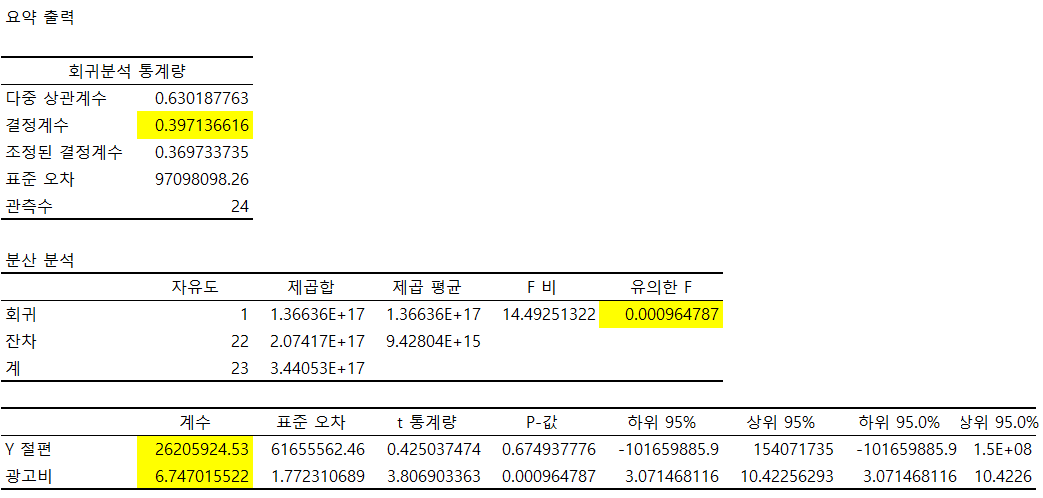
*결정 계수는 0~1 값을 가지며 1에 가까울수록 회귀 모형이 실제 값을 잘 설명한다
ex) 결정 계수가 0.4라면 이 회귀 모형이 실제 데이터 40%를 설명할 수 있다는 뜻
*유의한 F값이 0.05 미만이면 이 회귀 모형이 유의미하므로 사용 가능하다
ex) E값은 2.72정도로 F값에 0.05 미만인지 대략적으로 계산하여 사용하자
*Y = aX + b 에서 Y절편은 b값, a는 기울기를 뜻한다.

② 다중 회귀 분석
→ 독립 변수(X)가 여러 개일 때
→ 여러 개의 독립 변수(X1,X2,X3 ...)가 종속 변수(Y)값에 미치는 영향 파악

※ 데이터 분석 옵션을 사용한 이미지

*다중 회귀분석에서는 조정된 결정계수를 확인한다(여러 개의 독립 변수간의 오차를 컴퓨터가 조정한 값)
*결정 계수는 0~1 값을 가지며 1에 가까울수록 회귀 모형이 실제 값을 잘 설명한다
ex) 결정 계수가 0.96라면 이 회귀 모형이 실제 데이터 96%를 설명할 수 있다는 뜻
*유의한 F값이 0.05 미만이면 이 회귀 모형이 유의미하므로 사용 가능하다
ex) E값은 2.72정도로 F값에 0.05 미만인지 대략적으로 계산하여 사용하자
*P-값이 0.05 이하인 변수들이 종속 변수(매출)를 가장잘 설명하는 변수들이다
cf) 직원 수는 0.05보다 크지만, 거의 0.05에 가까우므로 직원 수가 더 많아지면 0.05 미만이 될 가능성이 있다
■ 시계열 분석
※ 시계열 데이터
: 일정 기간에 대해 시간의 함수로 표현되는 데이터
ex) 주가, 날씨(기온, 강수확률, 바람) 등
※ 시계열 데이터의 분석의 목표
: 과거 시계열 데이터 특성 파악 및 미래 데이터 예측 업무
※ 시계열 분석 방법의 종류

cf) 현실에서 나타나는 데이터들은 모두 비정상 데이터
*그런데 왜 정상 시계열 데이터 분석을 해야하는가?
: 비정상 시계열 데이터는 굉장히 분석하기 어렵다. 이 때문에 비정상 시계열 데이터 분석을 여러가지 방법을 써서 억지로 불규칙을 유발하는 요소들을 제외하고 정상 데이터 시계열 데이터로 만들어서 분석을 진행하는데, 이는 유의미한 결과를 얻을 수 있다.
: 엑셀에서 작업하기 조금 어렵기 때문에 우린 지수 평활법을 사용해 볼 것이다.
(다른 분석 방법은 R 또는 Python을 통해 구체적으로 시도해보자)
※ 시계열 분석 방법의 맹점
→ 아무리 고도화된 시계열 분석 방법을 사용하더라도 예측치는 항상 정확하지 않다!
cf) 지금 현존하는 최고의 시계열 데이터 분석을 사용하더라도 다음날 주가가 얼마로 오를지, 내릴지 맞추는 확률도 1/2도 안된다고 한다. 그만큼 주가를 형성하는 요소들이 많기 때문에 정확한 예측치를 낼 수가 없다. 절대적으로 맹신하면 안된다.
*시계열 데이터 분석으로 얻은 예측치도 조금 더 과학적으로 계산한 추정치일 뿐
→ 과학적인 방법으로 얻은 추정치에 실무자의 인사이트 반영이 중요하다!
● 지수 평활법
: 현재의 실제 값과 현재의 예측 값을 합산하여 미래의 예측 값을 구하는 방법
: 불규칙한 데이터들을 평평하게(정상 시계열 데이터화로) 만들어 분석하는 방법
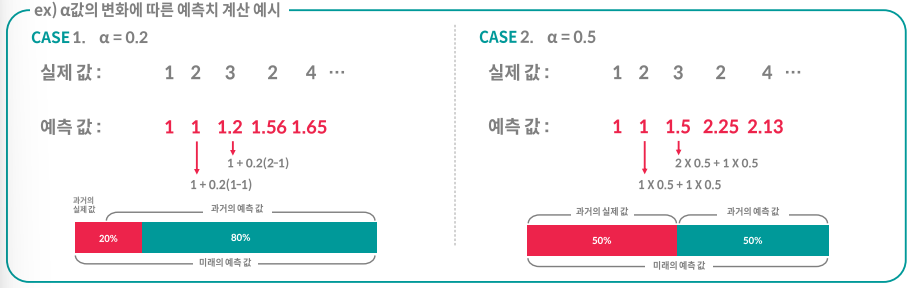
※ 단순 지수 평활법을 활용한 예측치 계산 방법
미래의 예측 값 = 과거의 실제 값 * α + 과거의 예측값 * (1-α)
미래의 예측 값 = 과거의 예측 값 + α(과거의 실제 값 - 과거의 예측 값)
α = 실제값을 반영할 가중치(0~1 사이의 값)
● FORECAST.ETS 함수
: 지수 평활법과 ETS방법을 통해 특정 시점의 미래 값을 예측
ETS(Error / Trend / Seasonality)
: 오차, 추세, 계절성을 반영해 시계열 데이터 분석
=FORECAST.ETS(예측할 날짜, 알고있는 실제 값들, 과거의 날짜들)
cf) 예전 버전의 FORECAST함수보다 최근 데이터가 더 가치 있다고 판단하여 반영하기 때문에 FORECAST함수를 사용했을 때와 FORECAST.ETS함수를 사용하여 나온 결과값이 다를 수 있다. (FORECAST.ETS함수가 더 정확하다)
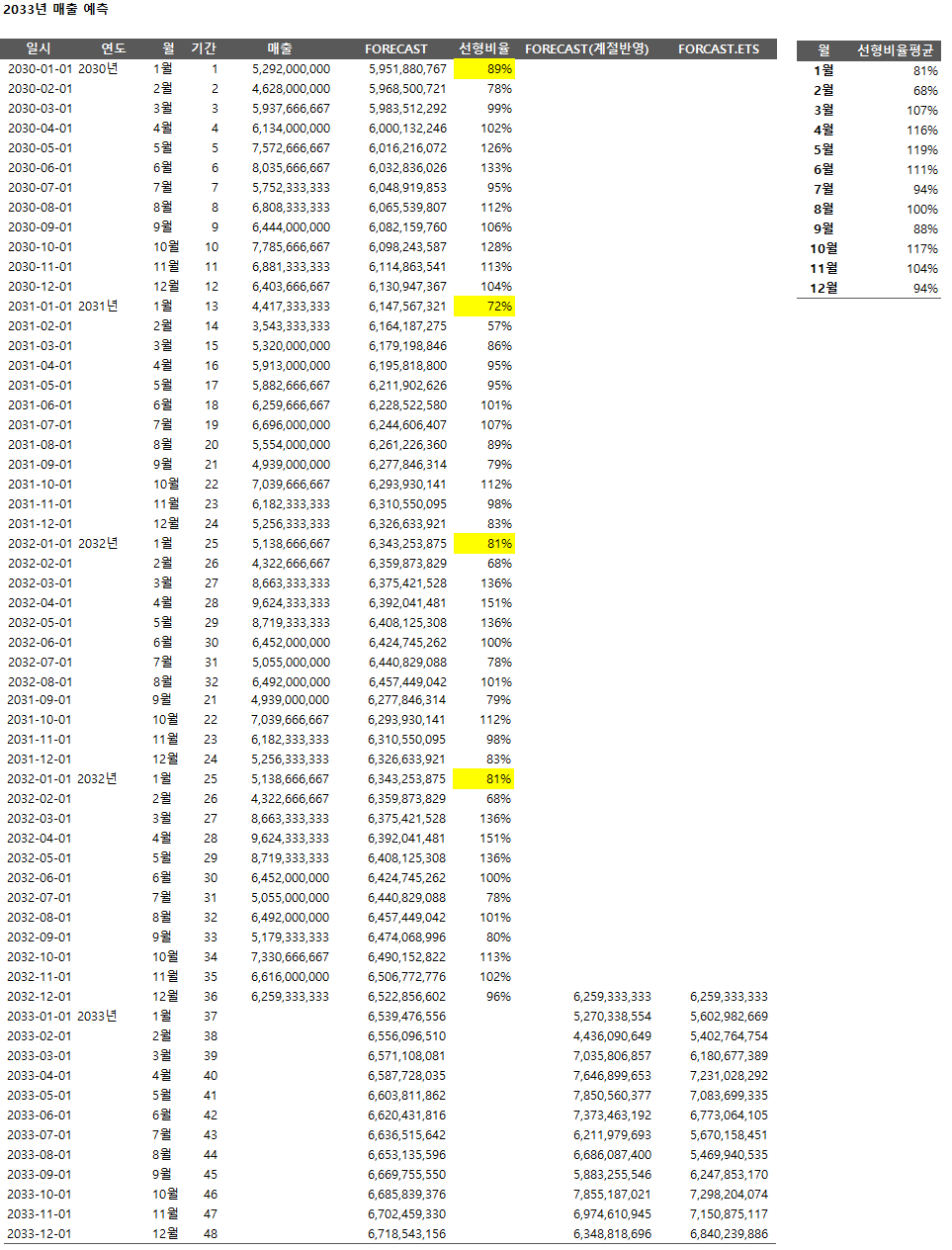
→ FORCAST함수를 이용하여 원래의 매출값과 나누어 선형비율을 표현하였다.
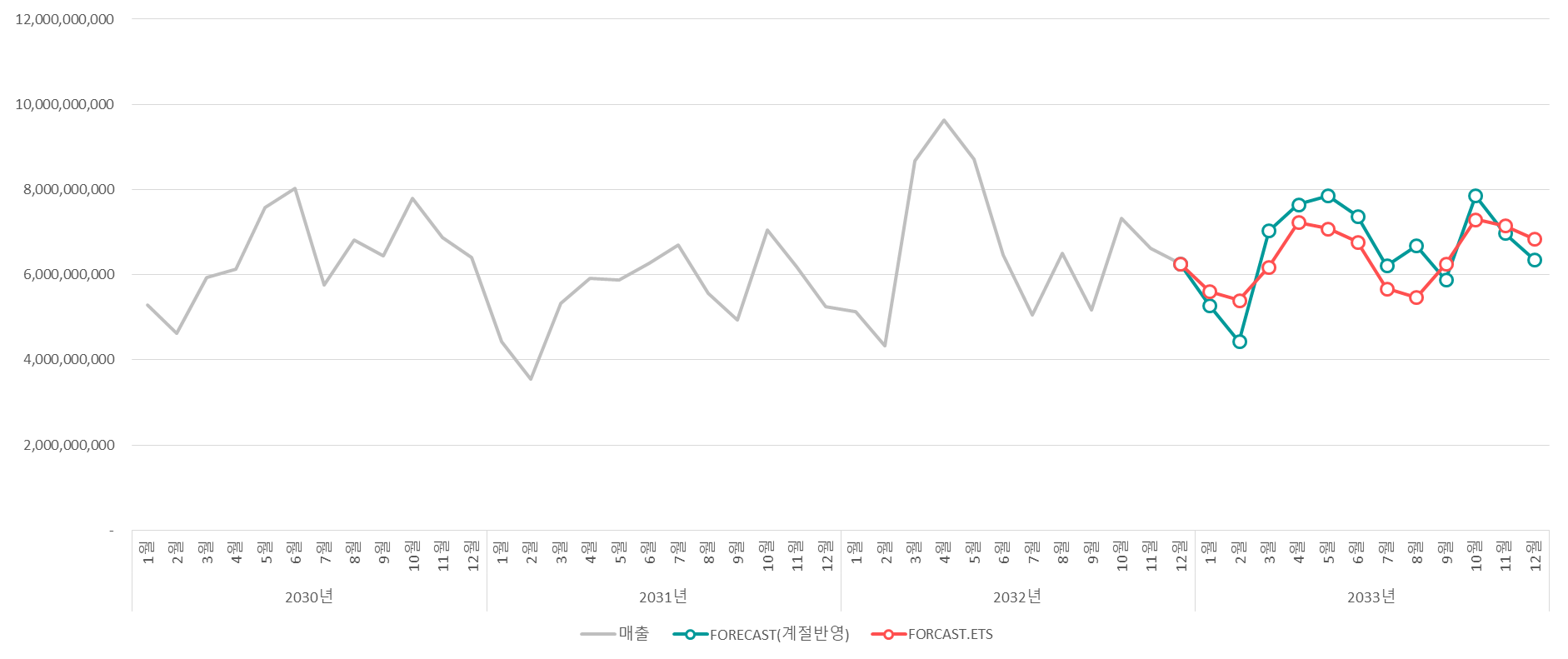
→ 이를 바탕으로 2033년의 매출을 예측하였고, FORCAST.ETS함수와 비교하여 꺾은 선 그래프로 시각화를 진행
★ 이러한 분석으로 대략적인 매출을 예측하고, 인사이트를 도출하여 매출이 낮은 구간에 어떠한 이벤트를 진행할지 생각해 볼 수 있을 것이다.
'Excel' 카테고리의 다른 글
| 데이터 시각화 (1) | 2023.03.21 |
|---|---|
| 데이터 전처리 (0) | 2023.03.12 |
| 엑셀을 이용한 탐색적 데이터 분석(EDA) (0) | 2023.03.08 |
| 엑셀 기초 (0) | 2023.03.08 |
| 엑셀로 데이터 분석을 하는 이유? (0) | 2023.03.08 |